无
”python url 爬虫 网络爬虫“ 的搜索结果
聊一聊Python与网络爬虫。 1、爬虫的定义 爬虫:自动抓取互联网数据的程序。 2、爬虫的主要框架 爬虫程序的主要框架如上图所示,爬虫调度端通过URL管理器获取待爬取的URL链接,若URL管理器中存在待爬取的URL链接,...
一、网络爬虫的定义 网络爬虫,即Web Spider,是一个很形象的名字。 把互联网比喻成一个蜘蛛网,那么Spider就是在网上爬来爬去的蜘蛛。 网络蜘蛛是通过网页的链接地址来寻找网页的。 从网站某一个页面(通常是首页...
本课程内容包括,网络爬虫的基础知识、开发网络爬虫涉及的文件操作、网络爬虫常用的库-requests...百度百科-爬虫程序结构设计模块导入当前页面的爬取解析器提取有效数据解析器提取href属性解析相关页面管理URL数据存储
网络爬虫(Web Spider)又称“网络蜘蛛”或“网络机器人”,它是一种按照一定规则从互联网中获取网页内容的程序或者脚本。网络爬虫会模拟人使用浏览器,上网自动抓取互联网中数据。Python 爬虫指的是用 Python来编写...

python爬虫入门基础代码实例和1个简单的python爬虫爬虫贴吧图片的实例 代码中给出了注释,并且可以直接运行 python爬虫主要操作步骤: 获取网页html文本内容; 分析html中图片的html标签特征,用正则解析出所有的...
什么是网络爬虫 网络爬虫又称网络蜘蛛,是指按照某种规则在网络上爬取所需内容的脚本程序。众所周知,每个网页通常包含其他网页的入口,网络爬虫则通过一个网址依次进入其他网址获取所需内容。 优先申明:...
在Python中可以使用urllib对网页进行爬取,然后利用Beautiful Soup对爬取的页面进行解析,提取出所有的URL。 什么是Beautiful Soup? Beautiful Soup提供一些简单的、python式的函数用来处理导航、搜索、修改分析树...
传统爬虫从一个或若干初始网页的URL开始,获得初始网页上的URL,在抓取网页的过程中,不断从当前页面上抽取新的URL放入队列,直到满足系统的一定停止条件 爬虫有什么用? 做为通用搜索引擎网页收集器。(google,...
python简单实现网络爬虫
标签: python
配合我的教程学习,只需要修改通用爬虫代码中的url和xpath路径,即可快速生成别的网站的python爬虫代码。十分适合新手小白练手用
Python以简单高效著称,在日常工作中用处非常多,处理文件、群发网络请求、爬网页信息等等,现把Python语法总结如下,供后续方便复习查阅。 文章目录一、变量 一、变量
聊一聊Python与网络爬虫。1、爬虫的定义爬虫:自动抓取互联网数据的程序。2、爬虫的主要框架爬虫程序的主要框架如上图所示,爬虫调度端通过URL管理器获取待爬取的URL链接,若URL管理器中存在待爬取的URL链接,爬虫...
本文主要针对基于Python的网络爬虫系统的设计与实现展开探究与讨论。系统采用Python做爬虫语言,采用beautifulsoup库进行数据爬虫,数据处理请求连接采用Resquests多线程方式进行URL处理。首先使用Python中的Scrapy...

本书从Python 3.6.4的安装开始,详细讲解了Python从简单程序延伸到Python网络爬虫的全过程。本书从实战出发,根据不同的需求选取不同的爬虫,有针对性地讲解了几种Python网络爬虫。 本书共10章,涵盖的内容有Python...

对于新手做Python爬虫来说是有点难处的,前期练习的时候可以直接套用模板,这样省时省力还很方便。


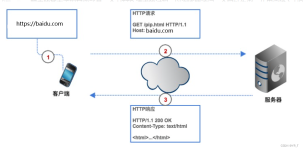
1 前言Python开发网络爬虫获取网页数据的基本流程为:发起请求通过URL向服务器发起request请求,请求可以包含额外的header信息。获取响应内容服务器正常响应,将会收到一个response,即为所请求的网页内容,或许包含...

我们首先来看下实例代码: from time import sleep ...def get_next_link(url): content = downloadHtml(url) html = etree.HTML(content) next_url = html.xpath("//a[@class='ch next']/@href") if next_ur
网络爬虫应用智能自构造技术,随着不同主题的网站,可以自动分析构造URL,去重。网络爬虫使用多线程技术,让爬虫具备更强大的抓取能力。对网络爬虫的连接网络设置连接及读取时间,避免无限制的等待。为了适应不同...
python网络爬虫开发技术文档,深入浅出的讲解了正则表达式的应用,URL解析等
今天小编就为大家分享一篇解决python爬虫中有中文的url问题,具有很好的参考价值,希望对大家有所帮助。一起跟随小编过来看看吧
本节内容:python 网络爬虫代码。一共两个文件,一个是toolbox_insight.py,是一个工具文件另一个是test.py,是一个用到toolbox_insight.py中工具的测试文件 代码示例:#filename: toolbox_insight.pyfrom sgmllib ...
推荐文章
- 【解决报错】java.sql.SQLException: Access denied for user 'root'@'localhost' (using password: YES)-程序员宅基地
- echart y轴显示小数或整数_echarts y轴显示16位小数-程序员宅基地
- Android客户端和Internet的交互_android与internet-程序员宅基地
- linux新建分区步骤_linux创建基本分区的步骤-程序员宅基地
- 信号处理-小波变换4-DWT离散小波变换概念及离散小波变换实现滤波_dwt离散小波变换进行滤波-程序员宅基地
- Ubuntu 10.10中成功安装ns-allinone-2.34_进入/home/ubuntu1/ns-allinone-2.34目录cd /home/ubuntu1-程序员宅基地
- 使用AES算法对字符串进行加解密_java 判断aes加密 与否-程序员宅基地
- DFS深度优先搜索(前序、中序、后序遍历)非递归标准模板_深度优先搜索 无递归-程序员宅基地
- 程序员面试字节跳动,被怼了~_字节跳动java什么技术站-程序员宅基地
- 嵌入式软考备考(五)安全性基础知识-程序员宅基地